關於圖像生成模型,先前已經介紹過 GAN、VAE 和 flow-based model,而從今天開始要介紹的是第四種模型 diffusion model(DM),現在非常知名的圖像生成模型 stable diffusion 就可以算是 diffusion model 的變體呢!
一般講到 diffusion model 多是在講 2020 年提出的 Denoising Diffusion Probabilistic Models,今天簡介的也是這個模型~那我們就開始吧!
下圖是 diffusion model 的架構圖: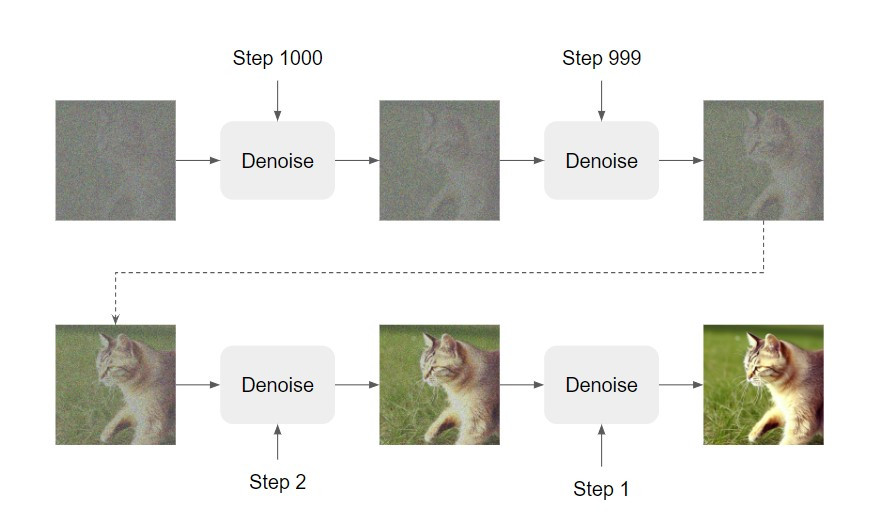
簡單來說,我們會輸入和預計生成影像相同大小的雜訊給模型,經過一次又一次降噪(denoise)的過程,影像的內容就會逐漸浮現。
Denoise 會有好幾個階段,使用的都是同一個 denoise 模組。但是不同階段影像中的噪聲嚴重程度不同,單純用同一個 denoise 模組效果可能會不太好,因此我們除了輸入待降噪的影像給模型以外,還要輸入一個代表這是哪個降噪階段的數字。
而一個 denoise 模組內部的結構如下圖: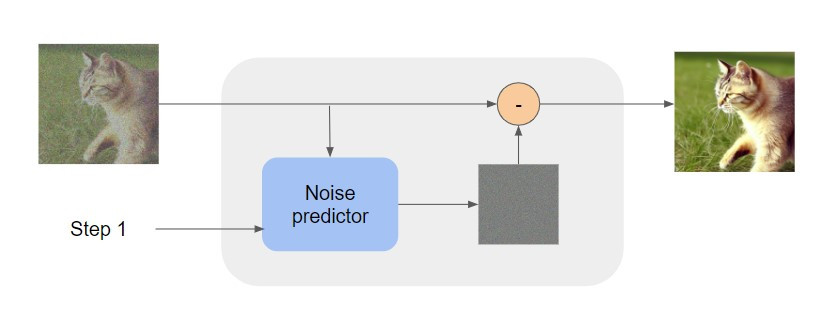
Denoise 模組內會有一個 noise predictor 預測輸入影像中的 noise 長什麼樣,然後再將輸入影像減去預測的 noise,就會得到降噪後的影像了!
看到這裡大家可能會有一個疑問:為什麼不讓 denoise 模組直接學習如何預測一張降噪後的影像呢?這是因為讓模型學習預測 noise 會是比較簡單的,而要模型預測一張降噪後的圖比較困難,產生影像的效果可能就不太好。
要訓練 diffusion model 生成影像,其實就是在訓練其中 noise predictor 預測影像中應該去除的 noise。然而,我們要怎麼得到 denoise 前後的成對影像來訓練模型呢?
其實準備訓練資料很簡單,我們可以把蒐集到的真實影像一步一步加上 noise,並把加上 noise 前的影像作為模型的學習目標,我們就可以訓練 diffusion model 了~
順帶一提,在 diffusion model 中,加噪音的過程會被稱為 forward process,而 denoise 的過程則會被稱為 reverse process。
實際在應用圖像生成模型時,我們都還是希望可以輸入一些文字指令,模型就能依據文字內容產生影像。因此在針對 text-to-image 任務訓練 diffusion model 時,我們會需要準備有文字標註的影像,而文字也會作為模型的輸入:
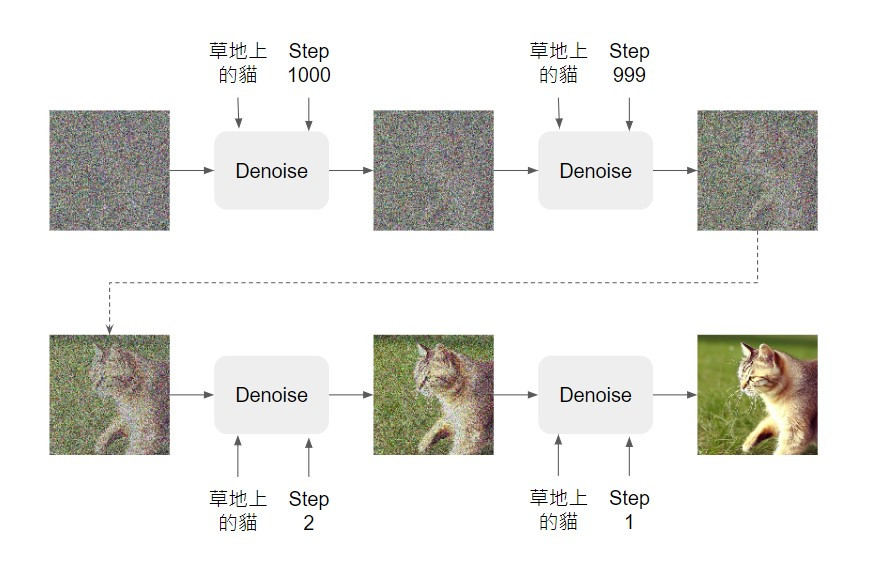
如上圖,我們總共會將待降噪影像、文字標註和 denoise 階段三項資訊都輸入模型,讓模型輸出一個降噪後比較清晰的影像~
當然要怎麼樣讓模型可以吃進文字、取得文字的意涵,進而連結到視覺的資訊,其實沒有那麼簡單,這在未來介紹 stable diffusion 的時候應該會提到~
今天就先這樣啦~明天開始會介紹 diffusion model 比較詳細演算法!


 iThome鐵人賽
iThome鐵人賽